
现在很多代码托管平台都提供基于 Docker 镜像的构建流水线,例如 GitHub、腾讯云等。
不同于 Jenkins 等传统的 CI/CD 工具,这种构建流水线对环境的要求和构建过程产生的副作用都非常小,在多次构建之间的差异也更小。因此,我推荐学习和使用此类构建工具。
而 Drone CI 就是这样的基于 Docker 镜像的构建流水线工具,也是本文的主题。
本博客也是使用它构建而来,点击链接 查看构建状态。
目前在 https://drone.paperplane.cc/ 上大约运行了 20 多个 CI/CD 流水线,截图如下:
背景
Drone 采用的是类似 k8s 的架构,其自身负责提供网站 UI 界面、提供 API 以及触发发起或停止构建操作,类似于 k8s 的 Master 节点;
而具体运行构建任务的则是交给各种 Drone Runner 来负责,类似于 k8s 的 Worker 节点。
Runner 有很多种类:
- 在 Docker 中构建的 Docker Runner;
- 通过 SSH 执行命令的 SSH Runner;
- 直接在本机执行命令的 Exec Runner 等。
各个 Runner 通过 RPC 连接到 Drone,负责执行 Drone 分配的构建任务。
通常来说,99% 的使用场景都是 Docker Runner,其他几种 Runner 的使用频率很低,更何况 Drone 和 Runner 本身就是基于 Docker 而部署的。本文也只讨论 Docker Runner 的使用场景。
纯前端项目的部署方式
对于纯前端项目而言,CI/CD 步骤一般是这样(克隆代码的步骤省略):
- 安装依赖,例如
yarn; - 运行测试,例如
yarn jest; - 编译打包,例如
yarn build; - 部署,可以直接把文件
scp或者rsync到服务器指定目录;
或者是打包成一个基于 Nginx 的镜像,让部署机运行这个镜像,以此暴露静态网页服务。
可以看出前端项目相对而言构建和部署都比较简单。
但是,yarn 的步骤可能会耗时很长;如果不在同一台机器上,把资源从构建机传输到部署机的过程也会比较耗时。本文尝试解决这类问题,寻求一种更为优化的方式来实现基于 Drone 的 CI/CD 的最佳实践。
之前有说过,纯前端项目可以打包成 Docker 镜像来部署,它的具体流程是:
- CI/CD 中运行
yarn安装依赖,yarn build构建资源; - 基于 Nginx 的 Docker 镜像打包一个新镜像,用它来提供服务。
我认为这只适合用做测试等场景,不适合用做生产环境,原因在下文。
做法是,先提供一个 Dockerfile 文件并写入:
FROM nginx
RUN rm /etc/nginx/conf.d/default.conf
ADD deploy/default.conf /etc/nginx/conf.d/
COPY dist/ /usr/share/nginx/html/然后在项目中创建 /deploy/default.conf 并写入:
server {
listen 80;
server_name _;
index index.html index.htm;
root /usr/share/nginx/html;
location / {
try_files $uri $uri/ /index.html =404;
}
}这样配置就提供好了,执行 docker build 命令,即可把项目打包成 Docker 镜像。
启动这个镜像无需任何额外参数或配置,启动后可以通过这个镜像的 80 端口来对外暴露静态网站服务。
但是,对于纯前端项目而言,我个人更倾向于使用 scp 或者 rsync 等方式把文件拷贝到服务器指定目录,也强烈推荐这样做:
如果使用对象存储作为 CDN 回源,可以在这一步直接把文件上传,这样就完成部署了;
旧版本的 JS/CSS 等文件可以保留,如果用户停留在旧版本页面上,未及时刷新,此时懒加载到旧模块不会白屏报错(推荐试试我开发的
use-upgrade);外层的 Nginx 统一控制访问行为,不需要多走一次容器内层的 Nginx,管理起来更方便;
如果使用镜像的方式,则还需要在部署机上调度容器,增加了一系列的操作。
当然这种方式也存在缺点,例如它没有很好的隔离性、需要访问较为底层的服务器资源(文件系统),但是整体来说还是最推荐的方式。
Docker 镜像的几种部署方式
本文只考虑基于 Docker 镜像部署的应用场景。
因为 Docker 镜像可以保证运行环境的一致性,还能做到服务器上多个不同 Node.js 版本的项目共存,甚至衍生出滚动更新(不停机升级)等很多玩法。 如果使用服务供应商的云原生服务,或者使用 k8s,那么使用 Docker 镜像部署就是必须的选择。
实际开发中,有两种 CI/CD 的场景:
- 构建和部署不在同一台机器上,此时部署 Docker 镜像时数据的安全传输是主要问题;
- 如果构建和部署在同一台机器上,或者处在同一内网,那我们的需求就变成了方便、高效。
针对这些诉求,下文会给出几种方案,你可以根据需求选用。
推送镜像到镜像仓库
这便是最简单直观的部署方式,也是最 “正确” 的方式。
它的流程如下:
- 提前准备一个镜像仓库,例如 Docker Hub;
- Drone CI 完成构建任务,输出好产物;
- 通过
docker build指令把项目打包成 Docker 镜像,然后使用docker push推送到镜像仓库; - 使用
ssh等方式连接到部署服务器,执行docker run --pull=always指令拉取镜像并运行。
这种部署方式,可以通过镜像仓库的镜像版本号实现快速的回滚等操作,而且便于多台机器分布式部署。
但是,它需求开发者自备镜像仓库,Docker Hub 只对免费用户提供一个私有镜像的额度,这肯定不够用;
开发者可以使用 registry、harbo 等工具自行搭建 Docker 镜像仓库;或者使用 Gitea、GitLab 的制品库功能;如果对镜像仓库的要求比较高,还可以付费使用例如阿里云、腾讯云的镜像仓库服务。
我之前也是一直这样做的,但是近期出现了一些小插曲:
近期我把网站服务器从腾讯云迁移到了 “雨云”,它的价格优惠较大、硬盘可弹性扩容、公网 IP 可以随便买,且其香港服务器的线路非常好。
但是,迁移后小厂的问题暴露了出来,例如:小厂没有 Docker 的内网加速域名,也没有制品库服务,服务器上拉取和上传镜像必须走固定带宽小水管。
而我的一些项目需求的 Docker 镜像体积较大,例如
paperplane-api这个项目的基础镜像就有 1.5 GB(压缩后也有近 900MB),打包依赖和代码后未压缩的体积竟然高达 2.5GB。上传镜像到制品库的耗时是不可接受的。虽然我有自搭的制品库,但小厂也不支持自建网络,Drone 运行的构建容器也没法配置 hosts,所以即使想推送到自搭制品库,流量也要经过外网绕一圈再回来。
我没有多余的服务器,构建和部署都在同一台机器上,因此可以寻找一种直接在本机上构建并部署,无需访问外部网络的部署方式。见下文的两种方案,它们是我后续的选择。
导出镜像为文件,并在部署机上导入
如果不想使用镜像仓库,我们可以利用 Docker 提供的功能,把镜像导出成文件,此时就可以利用例如 S3、OSS 等对象存储服务,以文件的方式来管理镜像。
这个功能用到了两条命令:
docker image save命令,可将某个镜像保存为文件;docker image load命令,指定一个文件把它加载还原为镜像。
这种方式相对于镜像仓库而言更为灵活,因为如果镜像需要在本机部署,那么文件直接存储到本机的某个已挂载的目录即可,宿主机可以直接使用这个镜像文件。
如果镜像不在本机部署,可以通过 S3 对象存储,或者是 rsync 等方式传输镜像文件到部署机上并导入。
但是,这种方式也存在一些问题:
- 导出、导入都需要额外的时间,这个过程也会占用硬件资源;
- 传输效率不高:使用镜像仓库时可以利用镜像的 “分层” 机制,跳过已存在哈希值的 “层” 来大幅降低传输数据量;但是这种方式把镜像整个打包为一个压缩包传输,没法利用 “分层” 的特性;
(下文会提到这个机制) - 部署动作只能由构建机发起:使用镜像仓库时,部署操作实际上可以看做是部署机在 “请求拉取” 最新的镜像;而这种传输镜像文件的部署方式,需要构建机来 “主动推送” 文件,主动方的角色变成了构建机,如果部署机较多,维护起来会很麻烦。
这种情况适用于本机需要构建+部署的场景,因为这免去了镜像文件的传输耗时;
不过,这种场景更推荐下一种方式,请看下一章节。
构建部署为同一台机器时,推荐使用 DinD
“DinD” 全名 “Docker in Docker”,即运行在 Docker 中的 Docker。在本机需要做构建+部署的场合,这是非常优选的方案,也是本文主要介绍的用法。
这里再次强调一下,此方式适合于 “构建和部署在同一台机器上” 的场合,也就是非常 “不正规” 的场景;公司业务之类的绝对不推荐这么做,用来做个人网站还是比较适合的。
我们从原理上入手,先来看看 Docker Runner 的 Docker Compose 配置文件:
services:
drone-runner-docker:
image: drone/drone-runner-docker
container_name: drone-runner-docker
volumes: # ↓ 注意这一行
- /var/run/docker.sock:/var/run/docker.sock上面的配置中,最引人注目是就是注释特别标注那一行。
可以看出,我们把宿主机的 Docker UNIX Socket 暴露给了 Runner。
原因是,Drone 的配置文件中,支持将宿主机的目录映射到构建过程中,而 Runner 本身也是一个容器,它不可能越过 Docker 直接把宿主机的文件直接挂在到另一个容器。
因此,Runner 必须能访问宿主机的 Docker,通过它来完成目录挂载等越级操作。透传 Docker UNIX Socket 给 Runner,这便给了 Runner 访问宿主机上 Docker 的能力。
而且,因为构建流程每一步都是跑在 Docker 容器中的,第一次运行时,Runner 必须自行去拉取这些容器的镜像,此时 Runner 就会使用宿主机的 Docker 来进行拉取镜像操作,这些拉取的镜像还会被持续存储在宿主机上,通过 docker images 命令直接看到。不过也正因如此,从第二次 CI/CD 开始便不再需要重新拉取一遍镜像了。
这就给了我们启发:
虽然 Runner 和宿主机是隔离的,但是可以通过上述方式,把宿主机的 Docker UNIX Socket 暴露给 Runner,这样一来镜像的构建操作实际上是在宿主机上发生的,构建产物会直接出现在 docker images 列表里,直接运行它即完成了部署。
可以简单理解为:CI 在 Runner 中完成,但打包镜像的动作在宿主机的 Docker 中完成。
这种方式非常适用于需要在同一台机器上构建+部署的场景。
基于上面的原理,我们需要使用 docker:dind 这个 Drone 镜像。
它原本的目的,是提供另一个能运行在 Docker 容器里的 Docker 环境,令我们可以使用 docker build 等命令;但只要我们把 /var/run/docker.sock 这个文件替换成宿主机的,那么所有 Docker 相关的命令和操作就都会由宿主机来完成。
给出一个实例 .drone.yml:
steps:
- name: build-image
image: docker:dind
volumes:
- name: dockersock
path: /var/run/docker.sock
commands:
- docker build --progress plain -t example/example:example .
volumes:
- name: dockersock
host:
path: /var/run/docker.sock这里可以看到,我们通过 volumes 配置来把宿主机的 /var/run/docker.sock 挂载到 DinD 容器中同样的位置,这样在 DinD 容器中执行的 Docker 命令,都会发生在宿主机的 Docker 守护进程上面。
这个构建步骤完成后,宿主机的镜像列表中便会出现构建好的 example/example:example 镜像,此时直接运行它即可。
这种方式速度快、具备隔离性,可以看做是跳过了网络传输步骤的基于推送和拉取镜像的 CI/CD 方式。
如果构建机和部署机是同一台,那么非常推荐这种方式。
使用 Exec Runner 构建成功后直接运行
Exec Runner 会直接在安装这个 Runner 的机器上运行命令,这和 Jenkins 很相似。
这种方式,牺牲了 Drone 作为 Docker 容器运行时的特性,无法做到环境和文件的隔离,是极度不推荐的方式。
这个场景也仅能适用于构建机和部署机是同一台的情况。如果是分别两台服务器,则这个步骤无法实现 “传递” 镜像,所以无法适用。
优化 CI/CD 的速度
这里给出项目 paperplane-api 的 构建流水线 记录:

可以看到在优化操作之前,每次构建所花费的时间很长,而优化后只需要一分钟左右。
实际上,这一分钟时间也有很大一部分浪费在 clone 操作上,真正 CI/CD 执行的时间加起来也就不到 30 秒钟:
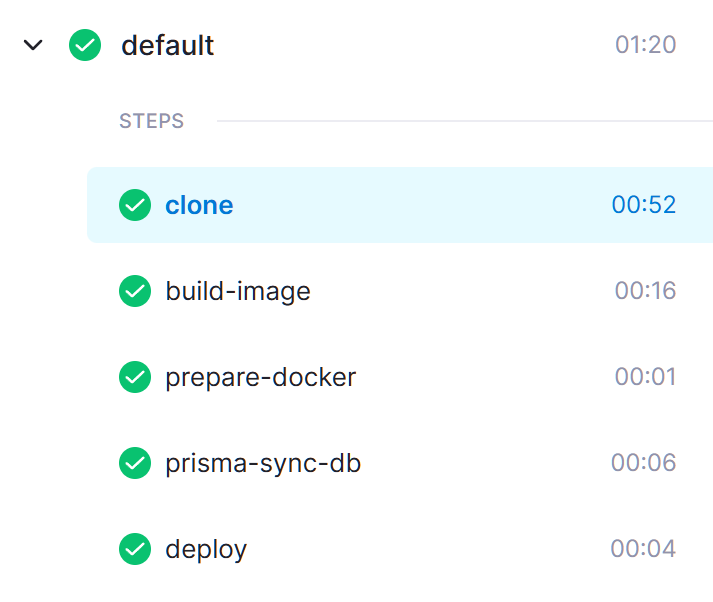
这个项目是一个最终打包为 Docker 镜像并在本机部署的 Node.js 后端项目,还使用到了 Prisma 做 ORM。
除去 clone 操作的耗时,原先超过四分钟的步骤,可以优化到只花费 30 秒钟,速度可以优化到 8 倍。
这便是本文接下来讲到的 CI/CD 速度优化的内容。
通过依赖项的缓存加快构建流程
前端项目每次 CI/CD 都需要安装依赖项,也就是 yarn 或 pnpm i。在这一步骤中,部署机需要从 npm 下载大量代码包,一般来说 node_modules 这个文件夹会很大,很容易就超出 GB 级别了,这些依赖项都需要在 CI/CD 流程中从网络上下载,非常耗时。
如果是本机直接执行 CI/CD 安装依赖,这些包会在本机硬盘上缓存。但是,Drone CI 每一个步骤都是基于 Docker,在完成步骤后,容器即被销毁,无法持久化缓存。
因此,我们需要想办法为 Drone 流水线持久化 npm 的缓存
Drone 的 Docker 流水线支持配置 volumes 来挂载宿主机的目录,可以将 yarn 的缓存目录对外挂载。
参考如下 .drone.yml 配置:
steps:
- name: install-deps
image: node:20
volumes:
- name: yarn-cache
path: /usr/local/share/.cache/yarn
commands:
- yarn
volumes:
- name: yarn-cache
host:
path: /path/to/host/dict # 服务器上的某个目录这段配置使用 node:20 镜像进行 yarn 安装依赖,但配置了 volumes,将目录 /usr/local/share/.cache/yarn 挂载到宿主机的目录。
每次安装依赖后,缓存会持久化保存在宿主机的磁盘上,下次构建也能用到这些缓存,速度就可以很快。
不过,Drone 默认不允许构建流程访问宿主机的磁盘,因为这存在风险。
我们需要在 Drone 中项目的 “Setting” 页面找到 “Trusted” 选项并开启,这样才允许使用 volumes 配置:

请注意:Drone 使用镜像中的默认用户来执行 CI/CD 命令;node 镜像中,默认用户是 root,也存在一个 node 用户不过不是默认的;可以通过 docker run --rm node:20-alpine whoami 来验证当前用户。
使用 npm 的用户可以通过 npm config get cache 来获取当前缓存存储的目录;
在 Linux 系统中通常位于:~/.npm;因此缓存目录是 /root/.npm。
对于 yarn 用户而言,可以通过 yarn cache dir 来获取当前缓存存储的目录;官方文档;
在 Linux 系统中,yarn 使用以下规则:
- 非
root用户,缓存目录位于:~/.cache/yarn; root用户,缓存目录位于:/usr/local/share/.cache/yarn;
镜像默认是 root,因此缓存目录是 /usr/local/share/.cache/yarn。
对于 pnpm 而言,可以通过 pnpm store path 来获取当前缓存存储的目录;官方文档。
注意:因为 pnpm 安装依赖时,node_modules 目录下全是硬链接,不是真实的文件,真实的文件存储于 “store-dir” 中,我称这个为缓存;
而 pnpm 还存在另一个 “cache-dir”,这个目录会被用来存储包的元数据、全局包、pnpm dlx 的缓存等等。
在 Linux 系统中,pnpm 使用以下规则:
对于 “store-dir”:
- 早期版本,它位于
~/.pnpm-store; - 自
v7.0.0以来,它位于~/.local/share/pnpm/store;
- 早期版本,它位于
但是,以上规则仅适用于存在 “home” 的磁盘,如果没有 “home” 目录,pnpm 使用项目所在的磁盘根目录下的
.pnpm-store来作为缓存目录,因为硬链接是不可能跨磁盘的;但是,在 Drone 流水线中运行时,pnpm 使用项目根目录下的
.pnpm-store来作为缓存目录;
项目所在的目录,基于你在.drone.yml中配置的 “workspace.path”,默认是"/drone/src",所以默认情况下缓存目录是/drone/src/.pnpm-store;
如果你修改了workspace,记得把挂载出去的缓存目录一并修改;这是因为 pnpm 的
node_modules目录里面都是硬链接,不存在真实的文件,而真实的文件如果放在其他目录,在下一个流水线步骤时这些文件都会丢失掉,只有项目根目录下的文件才是从头到尾一直持久化的;对于 “cache-dir”,它的默认目录是
~/.cache/pnpm;
如果你需要安装很多全局包,或者执行很多条pnpm dlx命令,也可以把这个目录挂载出来持久化;pnpm 的缓存和版本有关联,如果你在
package.json中指定了"packageManager": "pnpm@版本号",那么大版本号变动时,旧版本的缓存无法应用,必须重新下载安装;顺带提一嘴,使用
node镜像时,yarn是预装的,但pnpm不是预装的,正确的开启方式是执行corepack enable指令,而不是npm i -g pnpm。
为了测试以上内容,我创建了几个仓库:
- test-package-manager-cache 测试三个包管理工具在 Drone 流水线 中的缓存目录;
- test-package-manager-cache-default-workspace 测试三个包管理工具在默认
workspace时在 Drone 流水线 中的缓存目录。
你可以点开流水线的页面,查看日志输出,找到这些缓存目录的位置和结构。
请注意,有些依赖包自身内部有 preinstall 等脚本,会联网下载东西,或在本机进行编译(例如 sass、puppeteer、canvas 这些包,在国内的网络安装,甚至有时还会报错),仅将 npm 缓存挂载出来,无法加速这些特殊操作的耗时。
一般而言这些包编译出的产物是存储于 node_modules 下的,而不是存储于 npm 的缓存目录中。
查看 Drone 构建命令输出的耗时一栏,“Resolving packages”、“Fetching packages”、“Linking dependencies” 步骤可以很快完成,这便是缓存起到的作用;
但是 “Building fresh packages” 这一步可能会花费很长时间,上文所述的就是原因,这很难解决。
如果你想让这个步骤也加快,推荐继续阅读下文,利用 Docker 构建镜像的 “分层” 机制,实现对整个编译构建环境的缓存。
注意:下文的做法需要每次 CI/CD 都构建出一个 Docker 镜像,所以并不适用于前端项目。
通过 Layer 加快 Docker 镜像制作流程
本段内容受腾讯 AlloyTeam 的一篇 博文 的启发,强烈建议阅读。
Docker 镜像的产生需要通过 Dockerfile 来声明制作镜像的步骤。Dockerfile 是一个记录镜像制作过程中需要执行的操作的文件,我们在 docker build 的时候会依次执行其中的操作,大部分操作都可以产生 “Layer”,或者叫 “层”。
例如,执行 RUN 会产生 Layer,执行 COPY 把源码拷贝到镜像中,也会产生 Layer。
只有 Layer 的机制还不够,Docker 还会记录每次操作的哈希;构建镜像时,如果本地已有某个哈希值的 Layer,直接复用这一 Layer 即可,构建步骤就可以瞬间完成;推送镜像到仓库时,如果镜像仓库已有相同哈希值的 Layer,那么便可以跳过上传步骤,节约大量的网络传输流量。
只要保证 Layer 可以被复用,构建速度和上传速度都可以极大程度的加速。
这里还是以 paperplane-api 的流水线举例,可以看到大部分步骤都被缓存了,构建步骤瞬间完成:

但是,想复用 Layer 的机制,需要满足这样的条件:
- 对于任何 Dockerfile 指令而言,必须它之前的所有 Layer 都已使用缓存,它才能应用缓存;
- 通过
ADD或COPY向镜像中添加文件时,文件的内容和结构均没有任何变化时,这一 Layer 的哈希才会不变,这样才能应用缓存。
这两点机制是 Docker 用于在多次构建镜像时保证镜像的一致性的。但这些机制也给我们利用缓存机制提出了考验。
可以发现:
- 如果某一步没法缓存,为了防止它影响后面步骤的缓存,我们需要尽量把这个步骤移至最尾部执行;
例如把项目源码COPY进镜像,每次构建时项目源码肯定是发生过改动的,这一步肯定无法缓存,所以yarn build类似的指令在最后执行; - 以 yarn 来举例:安装依赖时
yarn指令必须要有package.json和 Lock 文件,而这两个文件一般来说不会特别频繁的修改,我们可以先只把这两个文件COPY到镜像,然后执行RUN yarn安装;这样一来,如果依赖项没有发生过任何变动,COPY操作和RUN yarn的哈希值都没有变化,这两个 Layer 可以应用缓存,从而使得安装依赖的步骤瞬间完成。
基于上面这两点结论,这里给出一个 Dockerfile 示例:
FROM node:20
# 指定工作区
WORKDIR /app
# 添加依赖配置到工作区,安装依赖
COPY package.json /app/
COPY yarn.lock /app/
RUN yarn
# 拷贝源码到工作区,打包编译
COPY . /app/
RUN yarn build
CMD [ "yarn", "start:prod" ]可以看到在 COPY . /app/ 这一步之前的步骤,都是可以应用缓存,尤其是安装依赖的耗时步骤,应用缓存后可以瞬间完成,极大程度减少 CI/CD 的时间。
如果你的项目比较复杂,例如用到了 .npmrc 来规定一些包的行为,或者,你是一个 monorepo 项目,结构复杂,此时这个指令需要写的很长很长,这里我强烈推荐由我开发的:docker-deps。
docker-deps 是一个 CLI 工具,专为把 Node.js 项目打包成 Docker 镜像而设计,用于提取项目的依赖定义文件以更好地命中 Layer 缓存。
它使用简单、功能强大,我为它编写了大量测试用例确保运行无误,且我自己的多个项目也在使用它。
(使用了 docker-deps,请直接按照下文的用法使用,忽略上面的改法。)
只需要在你的 .drone.yml 中的 “安装依赖” 步骤之前插入一个步骤:
- name: docker-deps
image: node:20.13.0
commands:
- npx -y docker-deps执行这个步骤后,工作区会出现一个 .docker-deps/,这里面包含了整个项目所有依赖文件,例如 package.json、Lock 文件、.npmrc;
然后,你需要编辑 Dockerfile,把下面两行插入到原本的 COPY 语句的前面:
原来:
COPY . <工作区目录>
RUN npm i
RUN npm build更改为:
COPY .docker-deps <工作区目录>
RUN npm i
COPY . <工作区目录>
RUN npm build这样就 OK 了。
经过这样的改造后,只要项目依赖相关的文件没有变动,构建镜像时就能命中之前的缓存,以 “CACHED” 的方式瞬间跳过 npm i,节约大量时间。
Layer 的缓存机制固然好,但使用它时也需要注意一些问题:
如果 Dockerfile 中需要执行一些带有副作用的操作,例如如果要 curl 发送一个请求,而 Docker 并不知道这一步有副作用,只要命令不被修改,这一步骤就会被缓存,从第二次执行开始就被跳过了,请求也就不再会被发出。
同样,使用 Prisma 等工具也会存在这种问题:
在 CI/CD 流程中,因为要在部署之前把数据库结构同步成最新代码的版本,我们需要为 Prisma 的 migrate deploy 操作单独准备一个步骤,通常把即将生产部署的镜像修改 command 启动命令并运行一次即可,因为生产部署的镜像中包含了最终的数据库结构、数据库连接配置,以及 npm 依赖项。
但 Prisma 会通过 postinstall 这个钩子来生成类型,也就是说在 yarn 这一步时,类型定义就已被生成好了;而我们只拷贝了 package.json 和 yarn.lock,并没有拷贝任何 Prisma 的 Scheme 文件,这会导致 Prisma 生成的类型为全空,而且会被缓存下来,后续无法执行 migrate deploy 操作,运行也会报错。
因此,在对 Prisma 这种 yarn 操作即存在副作用的工具进行 CI/CD 时,需要额外注意,副作用的步骤需要额外处理,不可使这类步骤被缓存。
一般来说,在安装完依赖后、打包或运行项目前,插入这两行即可:
# 注意下面两行是新增的
COPY /源码目录/to/prisma /项目目录/to/prisma
RUN yarn prisma generate这里我们额外增加了一个步骤,把 Prisma 的 Scheme 文件拷贝到镜像中,并专门执行一次 prisma generate 操作生成类型。如果 Scheme 文件没有任何改动,且 Prisma 没有任何需要应用的数据库结构迁移 SQL,这两步还是可以正常缓存的。
另外,这种方法最终构建出的是 Docker 镜像,也就是说前端项目非常不适合用这种方式,毕竟镜像中的文件不能直接复制出来,必须先运行起来才能通过 docker cp 指令复制。
利用 docker buildx 的 mount 功能
注意:这个功能必须开启 Docker 的 BuildKit,可以参考我的 这篇文章 来开启,这也会给 Docker 带来更多特性;
开启 BuildKit 会导致你原先的所有镜像和容器不可用,基本等于重装系统。更换到 BuildKit 后,原来使用的构建指令
docker build需要改成docker buildx build,后者才能利用 BuildKit 的新特性。
如果你觉得这样太麻烦,那么执行docker buildx install即可,这样原先的指令可以不用改继续用。
对于 Node.js 项目而非前端项目,最终需要打包成 Docker 镜像运行,安装依赖、打包构建等步骤均运行在 node 镜像内,因此,上面的 Drone 流水线挂载缓存的方式便不再适用。
此时,我们需要利用 Docker 提供的构建缓存功能,推荐阅读这个功能的 官方文档。
使用这个功能,需要我们修改 Dockerfile 中的安装依赖指令。
使用 npm 时,修改 Dockerfile,原先:
RUN npm i修改为:
RUN npm i这里,我们给 RUN 指令添加了一些参数,注意参数必须紧跟着 RUN 后面,--mount= 后面是完整的一段配置:
type=cache表示采用 “缓存模式”,这种模式可以在多次构建中持久化储存文件;id=npm为缓存指定一个 ID,用于复用;target=/root/.npm指定一个目录,表示缓存文件在镜像中的所在位置。
使用 yarn 时,修改 Dockerfile,原先:
RUN yarn修改为:
RUN yarn使用 pnpm 时,修改 Dockerfile,原先:
RUN pnpm i修改为:
RUN pnpm i此外,pnpm 还提供了 pnpm fetch 命令专门为 Docker 镜像这类场景,具体而言:
pnpm fetch不需要package.json,只需要pnpm-lock.yaml即可运行;- 这个指令将需要的包下载到缓存目录,但不会写入
node_modules;之后执行pnpm i时才会在node_modules里创建文件链接,此时就不用再花时间下载包了。
这个指令的好处是:
- 下载依赖项的耗时操作只会基于
pnpm-lock.yaml这个文件生成的 Layer,只要这个文件没发生更改,即使package.json被经常修改,也能利用 Layer 来加速构建; - 对于 monorepo 仓库而言,如果为了命中缓存,每个子包都要拷贝
package.json到镜像里非常麻烦(用我开发的docker-deps就不麻烦了,给自己的工具打个广告),使用pnpm fetch可以提前把需要的依赖全下载好,然后直接把整个项目都COPY进项目就行了。
修改 Dockerfile:
# 把 pnpm-lock.yaml 拷贝到工作区 WORKDIR 目录
COPY pnpm-lock.yaml <工作区目录>
RUN pnpm fetch
# 此时最耗时的操作已经完成了,整个项目都拷贝进去即可
COPY . <工作区目录>
# 安装时,加上 --offline 命令
RUN pnpm i --offline在 Docker 的 官网文档 中,给出了多个编程语言的示例,例如 Go 语言:
RUN go build -o /app/helloPython 语言:
RUN pip install -r requirements.txt等等。
FAQ
Q:为什么网上很多项目的 Dockerfile 都比较复杂,你用的是不是太简单了?
A:对于 Node.js 项目而言,更优的做法是 “安装依赖”、“编译构建”、“运行” 这些步骤,所使用的环境互相隔离开,这需要用到 Dockerfile 的 FROM ... AS ... 命令。
给出一个比较完善的 Dockerfile 配置:
FROM node:20 AS base
# deps 专门用来安装依赖
FROM base AS deps
WORKDIR /app
COPY package.json yarn.lock ./
# 注意,这里指令添加了 --prod 参数,此时不会安装 devDependencies 依赖
RUN yarn --prod --frozen-lockfile
# build 专门用来构建
FROM base AS build
WORKDIR /app
COPY package.json yarn.lock ./
RUN yarn --frozen-lockfile
COPY . .
RUN yarn build
# 运行
FROM base
WORKDIR /app
# 拷贝依赖项
COPY /app/node_modules /app/node_modules
# 拷贝打包编译后的源码
COPY /app/dist /app/dist
ENV NODE_ENV production
CMD ["node", "./dist/index.js"]这种方式更加完善,隔离性更好,如果你有需求,可以试一试;
注意依赖项一定要区分好,运行时需要的依赖项不要安装在 devDependencies 里。
Q:配置文件 .drone.yml 中,一定要使用绝对路径吗?
A:具体而言是这样的:
- 给 Drone 读取的都要使用绝对路径,连
~都不能有,例如workspace、volumes中的路径; - 流水线步骤中,可以随便使用各种相对路径。
Q:安装依赖时,是否需要加上 --frozen-lockfile 参数?
A:首先要说的是 npm 不支持这个参数,只有 yarn、pnpm 支持;
这个参数的作用是:安装时不会向 Lock 文件写入内容,然后只要安装的依赖和 Lock 不一致,或是不存在 Lock 文件,则安装步骤失败。
显然,在 CI/CD 流程中,是需要这个参数的,它可以做到更精确的锁定版本。
在使用 pnpm 配合 Drone 流水线时,可以省略这个参数:因为 pnpm 做了判断,只要检测到环境变量存在 CI=true 时,会自动使用 --frozen-lockfile 模式来安装依赖,而 Drone 会添加 CI=true 到流水线中;
不过,yarn 没有这个逻辑,所以如果使用 yarn,建议加上 --frozen-lockfile 参数。
npm 没有这个参数,不过,可以使用 npm ci 来代替,功能上类似。
Q:上面说了,Drone 会在流水线中注入 CI=true,这会不会导致什么意外?
A:其实不止是 Drone,大部分 CI/CD 工具或者在线服务都会加入这个环境变量;而且,很多 npm 包和构建工具也都会读取这个值。
举个最简单的例子,create-react-app 编译构建时,如果采取默认配置,只要检测到 CI 已开启,那么编译时 Warning 会直接失败。
Drone 除了 CI 这个变量,还会注入很多环境变量,例如分支名、标签名等等,不过这些都是以 DRONE 开头的,具体可以查看 官方文档。
Q:pnpm 好像很容易出问题啊?
A:是的,因为 pnpm 功能更强,配置项更多,而且从原理上与 yarn 和 npm 不同,所以它的迁移成本更高。
最简单直接的就是 package.json 中的 packageManager,这个版本要是不匹配,一上来就是报错。
又例如:最新的 pnpm v10 开始,执行 pnpm i 时默认不会运行依赖项的预构建命令,如果你使用 bcrypt、sharp 之类的工具,安装后跳过了它们的构建步骤会导致使用报错,必须在 package.json 中配置 pnpm.onlyBuiltDependencies 来开启这些包的预构建。
又例如:pnpm 在依赖项较多的项目或 monorepo 中运行时,依赖项的存储位置和 yarn 不同,有可能要通过 .npmrc 来进行 “提升” 配置;而且 pnpm 采用特殊的结构存储依赖项,依赖项如果在运行中生成文件,会被 pnpm 重定向到特殊的路径,例如 prisma 这类工具会在运行过程中生成文件,表现和 yarn 不同。